При использовании Elasticsearch для полнотекстового поиска по умолчанию используется поле _score, рассчитанное BM25, для сортировки в порядке убывания. Когда нам нужно использовать другие поля для сортировки в порядке убывания или возрастания, мы можем использовать поле сортировки и передать нужное поле сортировки и метод. Когда простое использование комбинации нескольких полей в порядке возрастания и убывания не может удовлетворить наши потребности, нам нужна функция пользовательской сортировки.Elasticsearch предоставляет DSL function_score для настройки оценки, чтобы мы могли сортировать в соответствии с пользовательской _score .
1. Первый пример
Сначала создайте новый индекс test_ratings.
{
"test_ratings_v1" : {
"aliases" : {
"test_ratings" : { }
},
"mappings" : {
"doc" : {
"properties" : {
"comment" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"create" : {
"type" : "date"
},
"id" : {
"type" : "integer"
},
"productId" : {
"type" : "integer"
},
"rating" : {
"type" : "integer"
},
"test" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"userId" : {
"type" : "integer"
}
}
}
},
"settings" : {
"index" : {
"refresh_interval" : "1s",
"number_of_shards" : "3",
"provided_name" : "test_ratings_v1",
"max_result_window" : "10000000",
"creation_date" : "1569227588095",
"number_of_replicas" : "0",
"uuid" : "cx7XVhITQnaBlqKtauZZow",
"version" : {
"created" : "6080199"
}
}
}
}
}
Затем импортируйте некоторые данные, базовый запрос выглядит так:
- DSL в запросе, заключенном в function_score, используется как условия запроса, которые мы обычно используем.
- field_value_factor представляет собой _score, рассчитанный запросом запроса, умноженный на значение поля рейтинга.
- отсутствует означает, что если значение рейтинга истинно, используйте 1 в качестве значения по умолчанию.
Подобно просьбе, мы можем найти те отзывы, которые имеют лайки в их заголовке, а также имеют высокий рейтинг, и, наконец, _score = _score * рейтинг (по умолчанию = 1)
GET /test_ratings/_search
{
"query": {
"function_score": {
"query": {"match": {
"title": "喜欢"
}},
"field_value_factor": {
"field": "rating",
"missing": 1
}
}}
}
2.field_value_factor
В приведенном выше примере есть краткая роль field_value_factor, а теперь посмотрим на некоторые параметры в field_value_factor.
2.1 field
Поле умножения, которое должно быть числового типа.
2.2 factor
Коэффициент умножения, вы можете настроить коэффициент умножения самостоятельно
2.3 missing
Определить значения полей по умолчанию
2.4 modifier
Исправленное значение умножения Иногда нехорошо умножать значение поля напрямую на _score, и значение поля необходимо исправить.Необязательные значения:
| опции | значение |
|---|---|
| none | По умолчанию |
| log | log(x) |
| log1p | log(1+x) |
| log2p | log(2+x) |
| ln | ln(x) |
| ln1p | ln(1+x) |
| ln2p | ln(2+x) |
| square | x^x |
| sqrt | квадратный корень х |
| reciprocal | величина, обратная х |
| Когда фактор и модификатор используются вместе, фактор имеет приоритет над модификатором. | |
| Возьмем журнал в качестве примера, окончательный счет будет таким: _score = _score * log(factor * x) | |
| Когда мы чувствуем, что разница между 0 и 1 больше, чем разница между 4 и 5, мы можем использовать журнал для исправления _score. | |
| ``` | |
| GET /test_ratings/_search | |
| { | |
| "query": { |
"function_score": {
"query": {"match": {
"title": "喜欢"
}},
"field_value_factor": {
"field": "rating",
"missing": 0,
"modifier": "log1p"
}
}} }
当默认值为0的时候,使用log会报错,因此可以使用log1p来修正。
# 3.script_score
当我们使用field_value_factor和functions内简单的weight无法满足业务的时候,可以使用Elasticsearch提供的Painless脚本来自定义排序函数。
painless语法参考:[https://www.elastic.co/guide/en/elasticsearch/painless/6.8/painless-examples.html](https://www.elastic.co/guide/en/elasticsearch/painless/6.8/painless-examples.html)
一个简单的用法如下:
ПОЛУЧИТЬ /test_ratings/_search { "запрос": {"function_score": { "запрос": {"совпадение": { "название": "Нравится" }}, "boost_mode": "заменить", "script_score": { "скрипт": { "параметры": { "а":1, "Би 2 }, "source": "_score + params.b * doc['rating'].value" } } }} }
## 3.1 params
自定义参数
## 3.2 source
指定脚本,可以使用doc['f']的方式访问原始字段值,也可以用_score访问计算后的score值
# 4.random_score
使用random_score可以让不同的人请求得到不同的排序结果,而同一个人请求可以得到相同的结果,使用如下:
ПОЛУЧИТЬ /test_ratings/_search { "запрос": {"function_score": { "запрос": {"совпадение": { "название": "Нравится" }},
"random_score": {
"seed": 1,
"field": "userId"
},
"boost_mode": "replace"
}} }
## 4.1 seed
指定随机的种子,相同的种子返回相同排序,每个种子会为每个文档生成一个0-1的随机数,改随机数就是random_score的返回值,可以和其他filter或者外部打分一起使用。
## 4.2 field
对于相同shard的相同field的值,产生的随机数一样,因此在使用的时候,尽量选择值不一样的field。
# 5.functions
上面的例子中,每一个doc都会乘以相同的系数,有时候我们需要对不同的doc采用不同的权重。这时,使用functions是一种不错的选择。基本的用法如下:
ПОЛУЧИТЬ /test_ratings/_search { "запрос": { "function_score": { "запрос": { "совпадение": { "название": "Нравится" } }, "функции": [{ "фильтр": { "срок": { "Идентификатор пользователя": 209983 } }, "вес": 5 }, { "фильтр": { "срок": { "рейтинг": 5 } }, "вес": 2 } ], "буст": 2, "score_mode": "макс", "boost_mode": "умножить", "мин_счет": 18, "макс_буст": 4 } } }
## 5.1 filter
表示每一个不同分值的过滤器。
## 5.2 weight
表示对应的权重
上诉例子表示:对搜索召回的结果,userid=209983的doc,weight为5,rating=5的doc的weight为2
## 5.3 functions内其他内部参数
functions内支持script_score和field_value_factor等参数
# 6. function_score其他外部参数
还是以4中的例子来分析其他的外层参数
## 6.1 score_mode
表示functions内的每一项的计算方式,可选的计算方式有:
| 选项 | 含义 |
| :-------- | --------:|
|multiply |functions内每一项weight相乘|
|sum |functions内每一项weight相加|
|avg |functions内的weight求平均值|
|first |functions内的第一个weight值|
|max |functions内的最大weight|
|min |functions内的最小min|
## 6.2 max_boost
对functions计算的score的限制,表示functions返回的最值。适用field_value_factor等其他场景
## 6.3 boost
对functions计算出来的结果,再做相乘的系数。适用field_value_factor等其他场景
## 6.4 boost_mode
对boost和functions结果的乘积 和原始_score之间的计算方式。适用field_value_factor等其他场景,可选值为:
| 选项 | 含义 |
| :-------- | --------:|
|multiply |结果和原始_score相乘|
|replace |用计算结果替换原始_score |
|sum |结果和原始_score相加 |
|avg |结果和原始_score求平均值 |
|max |求结果和原始_score最大值 |
|min |求结果和原始_score最小值 |
## 6.5 min_score
限制最后召回的最低得分
## 6.6 weight
在外部也可以用weight,对每个文档乘一个系数。
# 7.衰减函数
有些时候我们需要某个字段等于一个特定值时分数最高,然后往两边或者一边递减,比如地理位置或者价格区间。这个时候可以使用衰减函数。基本使用如下:
{ "запрос": { "function_score": { "запрос": { "совпадение": { "название": "Нравится" } }, "гаусс": { "рейтинг": { "происхождение": "2", "смещение": "1", "шкала": "0,5", "распад": "0,5" } }, "boost_mode": "заменить" } } }
其中rating是field名,gauss是衰减函数名
## 7.1 fiend内部参数
| 选项 | 含义 |
| :-------- | --------:|
|origin |最佳值的位置,这个位置的score为1|
|offset |最佳值两边的范围,在(origin-offset, origin+offset)范围内都是最大score:1|
|scale |衰减距离,从offset再往外scale衰减到指定decay值|
|decay |指定的衰减值,到达scal的距离,衰减到decay|
## 7.2 衰减函数
目前支持三种衰减函数:gauss、exp、linear
衰减函数和参数见下图,参考[https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl-function-score-query.html#function-random](https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl-function-score-query.html#function-random)
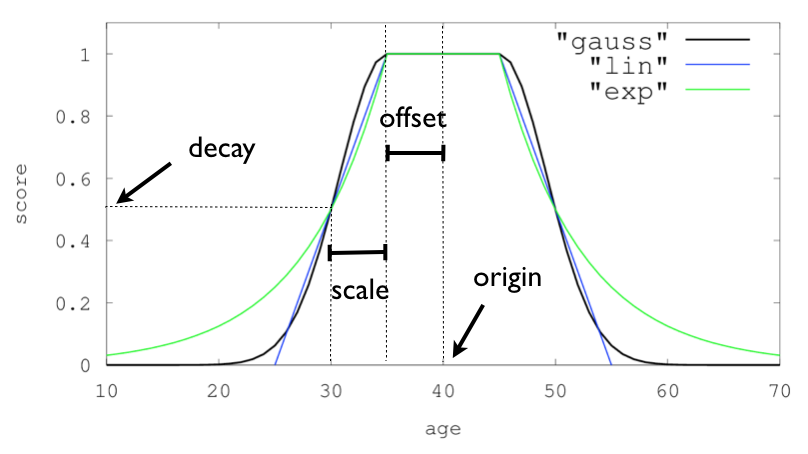
## 7.3 multi-values fields
在计算field的值到origin的距离时,如果field是一个多值的字段,则可以通multi_value_mode字段,来设置参与距离计算的值,可选值为:
| 选项 | 含义 |
| :-------- | --------:|
|min |field内到origin的最小距离|
|max |field内到origin的最大距离|
|avg |field内数组到origin的平均距离|
|sum |field内数组到origin的距离之和|
# 8.总结
利用Elasticsearch的function_score功能,可以灵活的对搜索结果进行排序。但是在使用过程中尽量少使用script_score,script_score性能会有一些影响。
更多精彩内容,请关注公众号
