предисловие
-
Статья была впервые опубликована в публичном аккаунте WeChat [Code Ape Technology Column]
-
Недавно я работал над соответствующим содержанием дедупликации содержимого чтения в системе Рекомендации, и я только что использовал фильтр Bloom, поэтому я написал статью для записи и поделиться ее.
-
Длина статьи не очень велика, в основном она рассказывает об основной идее фильтра Блума, каталог выглядит следующим образом: 
Что такое фильтр Блума?
-
Фильтр Блума — это структура данных, состоящая из битового **массива** длиной m бит и k **хеш-функций**. Битовые массивы инициализируются `0`, и все хеш-функции соответственно могут хешировать входные данные настолько равномерно, насколько это возможно.
-
Когда **вставляете** элемент, его данные преобразуются в `k` хэш-значений с помощью `k` хеш-функций, эти `k` хеш-значений будут использоваться в качестве `нижнего индекса` битового массива, и Установите значение соответствующего нижнего индекса в массиве на «1».
-
При **запросе** элемента он также преобразует его данные в `k` хеш-значений (индексы массива) с помощью `k` хэш-функций и запросит значение соответствующего индекса в массиве, если есть нижний индекс Значение нижнего индекса `0` указывает, что элемент не должен быть в наборе.Если все значения нижнего индекса равны `1`, это указывает, что элемент `возможно` в наборе. **Почему можно быть в наборе? ** Поскольку возможно, что на один или несколько индексов, значение которых равно 1, влияют другие элементы, это так называемое «ложное срабатывание», которое будет подробно описано ниже.
-
**Невозможно удалить элемент**, почему? Поскольку хеш-значение удаляемого элемента может совпадать с хэш-значением элемента в коллекции, удаление этого элемента приведет к удалению и других элементов.
-
На рисунке ниже показан пример фильтра Блума с m=18, k=3. Три элемента x, y и z в наборе хешируются в битовый массив тремя разными хеш-функциями. При запросе элемента w элемент w отсутствует в наборе, поскольку один бит равен 0. 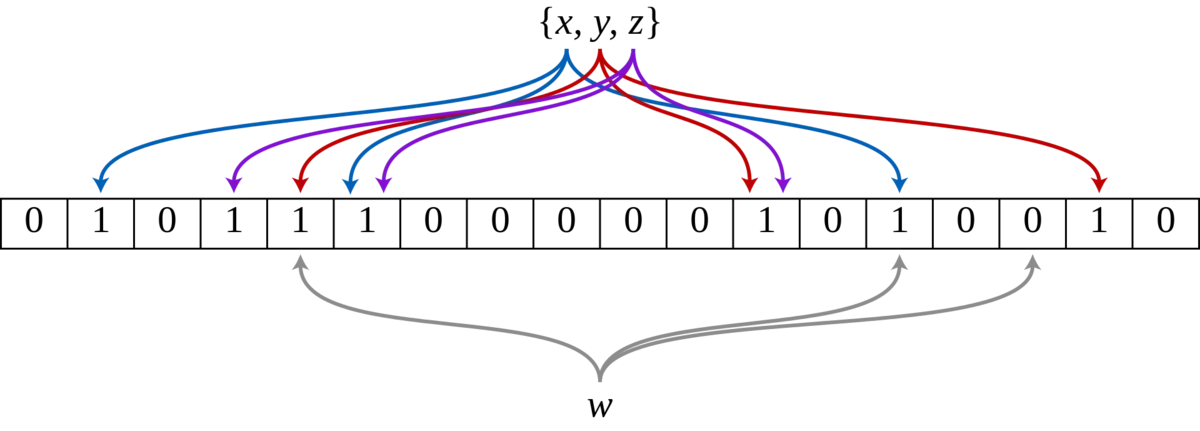
Расчет вероятности ложного срабатывания
-
Ложные срабатывания — болевая точка фильтра Блума, поэтому нам нужно сделать все возможное, чтобы уменьшить вероятность ложных срабатываний, а в это время нам нужно рассчитать вероятность ложных срабатываний.
-
Предположим, наша хэш-функция выбирает биты в массиве битов с равной вероятностью. Конечно, при проектировании хэш-функции также следует стремиться к равномерному распределению.
-
Вставляет элемент в фильтр Блума с длиной битового массива `m`, одна из его хеш-функций установит определенный бит в `1`. Следовательно, после вставки элемента вероятность того, что бит все еще равен 0, равна:
-
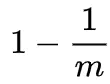
-
Есть `k` хэш-функций и вставлено `n` элементов, вероятность того, что бит по-прежнему равен 0, может быть получена естественным образом: 
-
И наоборот, вероятность того, что он был установлен в «1», составляет:
-
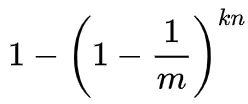
-
То есть, если после вставки `n` элементов мы обнаруживаем элемент, которого нет в наборе, то вероятность ложного сообщения о том, что он находится в наборе (то есть, все биты, соответствующие хеш-функции, равны `1) `) это: 
-
Когда «n» относительно велико, согласно предельной формуле, частота ложных срабатываний может быть аппроксимирована:
-
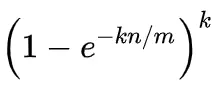
-
Следовательно, когда количество хеш-функций «k» известно, можно сделать следующие выводы:
-
Чем больше длина битового массива m, тем ниже уровень ложных срабатываний.
-
Чем больше число n вставленных элементов, тем выше уровень ложных срабатываний.
-
преимущество
-
Представленный битовым массивом, без сохранения самих данных, экономия места имеет абсолютное преимущество перед традиционным методом.
-
Эффективность времени очень высока.Будь то вставка или запрос, его нужно преобразовать только с помощью простой хеш-функции, а временная сложность составляет «O (k)».
недостаток
-
Существует вероятность «ложного срабатывания», и это не подходит для сценариев с высокими требованиями к точности.
-
Вы можете только вставлять и запрашивать, но не удалять элементы.
Сценарии применения
-
Фильтры Блума имеют множество применений, но основная функция — удаление дубликатов Вот несколько сценариев использования.
Обнаружение повторяющихся URL-адресов сканером
-
Представьте себе, Baidu — это рептилия, она будет регулярно собирать информацию о крупных веб-сайтах, статьях, а затем, как убедиться, что просканированная до статьи информация не повторяется, она будет хранить URL-адрес фильтра Блума, каждый раз перед началом сканирования фильтра Блума. определяет, существует ли URL-адрес, что позволяет избежать дублирования сканирования. Конечно, это может быть ложным срабатыванием, но пока ваш битовый массив достаточно велик, чтобы «вероятность ложного срабатывания была низкой, с другой стороны, вы думаете, что Baidu позаботится об ошибках такого рода, ваша статья может быть связана с тем, что вероятность ложного срабатывания не включена в Baidu повлиять на вас?
Функция рекомендации Douyin
-
Читатели и друзья, не должно быть никого, кто никогда не проводил Douyin. Douyin показывает вам повторяющиеся видео каждый раз, когда вы проводите пальцем? Как он гарантирует, что рекомендуемый контент не будет повторяться?
-
Проще всего подумать, что Douyin будет записывать историю просмотра пользователя, а затем исключать его из истории. Это обходной путь, но как насчет производительности? Излишне говорить, что любой, у кого есть немного здравого смысла, знает, что это невозможно.
-
Для решения этой повторяющейся проблемы фильтр Блума имеет абсолютное преимущество и может быть легко решен.
Предотвратить проникновение в кеш
-
Проникновение в кэш относится к запросу фрагмента данных, который не находится ни в базе данных, ни в кеше, база данных будет запрашиваться все время, и давление доступа к базе данных будет продолжать расти.
-
Фильтр Блума также очень эффективен в решении проблемы проникновения в кеш, поэтому я не буду здесь вдаваться в подробности, а напишу в следующей статье.
Как реализовать фильтр Блума?
-
После понимания идеи дизайна фильтра Блума реализовать фильтр Блума на самом деле очень просто.
Реализация Redis
-
После Redis 4.0 запустилась функция плагина, а с докером установлено следующее:
docker pull redislabs/rebloom docker run -p6379:6379 redislabs/rebloom
-
После завершения установки подключитесь к Redis и выполните команду:
redis-cli
-
Что касается конкретного использования, то оно здесь демонстрироваться не будет, достаточно посмотреть официальные документы и туториалы, и пользоваться им все равно очень просто.
Реализация гуавы
-
Guava поддерживает реализацию фильтров Блума, и фильтр Блума легко реализовать с помощью гуавы.
1. Создайте фильтр Блума
-
Создайте фильтр Блума следующим образом:
Фильтр BloomFilter = BloomFilter.create( Воронки.integerFunnel(), 5000, 0,01); //вставлять IntStream.range(0, 100_000).forEach(filter::put); //Проверяем, существует ли он логическое значение b = filter.mightContain(1);
-
`arg1`: используется для преобразования входных данных любого типа T в данные базового типа Java, здесь преобразованы в байты
-
`Arg2`: байтовая база байта
-
`arg3`: ожидаемая вероятность ложного срабатывания
2. Оценить оптимальные значения m и k
-
Guava сделал свой собственный алгоритм для базы (m) байтового массива и количества хеш-функций k на нижнем уровне, Исходный код выглядит следующим образом:
//Расчет значения m статический длинный оптимальныйNumOfBits(long n, double p) { если (р == 0) { р = удвоить.MIN_VALUE; } return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2))); }
//Вычисление значения k статический интервал оптимальныхNumOfHashFunctions(long n, long m) { // (m / n) * log(2), но избегайте усечения из-за деления! return Math.max(1, (int) Math.round((double) m / n * Math.log(2))); }
-
Если вы хотите понять принцип расчета гуавы, вам нужно продолжить процесс, полученный из вышеизложенного.
-
Согласно методу приближенного расчета частоты ложноположительных результатов, если уровень ложноположительных результатов должен быть как можно меньше, при заданных условиях m и n значение «k» должно быть:
-
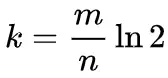
-
Подставляя k в формулу из предыдущего раздела и упрощая, мы можем разобраться в связи между ожидаемой частотой ложных срабатываний p и m, n: 
-
Конвертировано в:
-
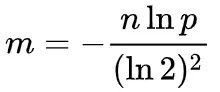
-
На основании вышеизложенного анализа делаются следующие выводы:
-
Если вы задаете ожидаемую частоту ложных срабатываний p, то оптимальное значение m является линейным с ожидаемым количеством элементов, n.
-
Оптимальное значение k фактически связано только с p, независимо от m и n, то есть: 
-
Подводя итог двум приведенным выше выводам, важно определить значение «p» и значение «m» при создании фильтра Блума.
-
Суммировать
-
До сих пор здесь было представлено знание фильтра Блума.Если вы считаете, что Чен написал хорошо, пожалуйста, сделайте репост этого в волне основных моментов, и поддержка читателей будет моей большой поддержкой.
-
** Кроме того, если вы хотите пообщаться с Ченом в частном чате или присоединиться к группе обмена, ответьте на ключевое слово «добавить группу» и добавьте WeChat Чена в официальную учетную запись, и Чен привлечет вас в группу как можно скорее. . **
плечи гигантов
-
https://blog.csdn.net/u012422440/article/details/94088166
-
https://blog.csdn.net/Revivedsun/article/details/94992323