Предыдущая статья оптимизирует базу данных с точки зрения экземпляра и оптимизирует производительность базы данных путем настройки некоторых параметров. Но некоторые «плохие» SQL также могут вызывать замедление запросов к базе данных и влиять на бизнес-процессы. В этой статье база данных оптимизируется с точки зрения SQL для повышения эффективности работы SQL.
Определите проблему SQL
О том, есть ли проблема с SQL, можно судить по двум внешним признакам:
- представление на системном уровне
- Высокое потребление процессора
- IO ждать серьезно
- Время отклика страницы слишком велико
- В журнале приложения есть ошибки, такие как тайм-аут
можно использоватьsarЗаказ,topКоманда для просмотра текущего состояния системы.
также черезPrometheus、GrafanaОтслеживайте состояние системы с помощью других инструментов мониторинга. (Если вам интересно, вы можете прочитать мою предыдущую статью)
- Представление оператора SQL
- длинный
- Время выполнения слишком велико
- Получить данные из полного сканирования таблицы
- Строки и стоимость в плане выполнения очень большие
Длинный SQL легко понять, если кусок SQL слишком длинный, читабельность определенно будет плохой, а частота проблем определенно будет выше. Чтобы лучше судить о проблеме SQL, мы должны начать с плана выполнения, как показано ниже:
План выполнения сообщает нам, что этот запрос прошел полное сканирование таблицы.Type=ALL, строки очень большие (9950400), в принципе можно судить, что это "со вкусом" SQL.
Получить проблемный SQL
Различные базы данных имеют разные методы сбора данных.Ниже приведены инструменты получения медленных запросов SQL для текущих основных баз данных.
- MySQL
- журнал медленных запросов
- средство тестирования loadrunner
- ptquery Percona и другие инструменты
- Oracle
- AWR-отчет
- Инструмент для тестирования loadrunner и т. д.
- Связанные внутренние представления, такие как v$sql, v$session_wait и т. д.
- Инструмент мониторинга GRID CONTROL
- База данных Деймона
- AWR-отчет
- Инструмент для тестирования loadrunner и т. д.
- Инструмент мониторинга производительности Dameng (dem)
- Связанные внутренние представления, такие как v$sql, v$session_wait и т. д.
Навыки написания SQL
Существует несколько общих методов написания SQL:
• Индекс добросовестного использования
Если индекс меньше, запрос выполняется медленно; если индекс больше, пространство велико, и индекс необходимо динамически поддерживать при выполнении операторов добавления, удаления и модификации, что влияет на производительность.
Высокая избирательность (меньшее количество повторяющихся значений) и частые ссылки по тому, где требуется индексирование B-дерева; общие столбцы соединения должны быть проиндексированы; запросы сложных типов документов используют полнотекстовое индексирование для повышения эффективности; индексирование должно обеспечивать баланс между запросом и производительностью DML; При создании составного индекса обратите внимание на запрос на основе не ведущих столбцов.
• Используйте ОБЪЕДИНЕНИЕ ВСЕХ вместо ОБЪЕДИНЕНИЯ
Эффективность выполнения UNION ALL выше, чем у UNION, и UNION необходимо переупорядочивать при выполнении; UNION необходимо сортировать данные
• Избегайте обозначения select *
При выполнении SQL оптимизатору необходимо преобразовать * в определенный столбец, каждый запрос должен возвращаться к таблице, а покрывающий индекс использовать нельзя.
• Поля JOIN рекомендуется индексировать
Как правило, поля JOIN индексируются заранее.
• Избегайте сложных операторов SQL.
Повышение удобочитаемости; предотвращение вероятности медленных запросов; возможность преобразования в несколько коротких запросов и их обработка бизнес-стороной
• Избегайте обозначения, где 1=1.
• Избегайте записи порядка с помощью rand(), например
RAND() заставляет столбец данных сканироваться несколько раз
SQL-оптимизация
План реализации
Чтобы выполнить оптимизацию SQL, вы должны сначала прочитать план выполнения, который подскажет вам, где эффективность низка, а где необходима оптимизация. Давайте возьмем MYSQL в качестве примера, чтобы увидеть, каков план выполнения. (План выполнения каждой БД разный, нужно разбираться самому)explain sql
| поле | объяснять |
|---|---|
| id | Каждая выполняемая операция независимо определяет порядок, в котором выполняются операции с объектами. Чем больше значение id, тем выполняется первая. Если одинаково, порядок выполнения сверху вниз. |
| select_type | тип каждого предложения select в запросе |
| table | Имя объекта, с которым манипулируют, обычно имя таблицы, но есть и другие форматы. |
| partitions | Совпадающая информация о разделе (NULL для неразделенных таблиц) |
| type |
Тип операции соединения |
| possible_keys | возможные индексы |
| key | Фактически используемый оптимизатором индекс (самая важная колонка) от лучших к худшим типам соединенияconst,eq_reg,ref,range,indexиALL. когда он появитсяALLКогда текущий SQL имеет «дурной вкус» |
| key_len |
Длина ключа индекса, выбранного оптимизатором, в байтах |
| ref |
Указывает ссылочный объект объекта, над которым работают в этой строке, если нет ссылочного объекта, он равен NULL. |
| rows |
Количество кортежей, просканированных при выполнении запроса (для innodb это значение является оценочным) |
| filtered | Процент кортежей, чьи данные в таблице условий отфильтрованы |
| extra | Важная дополнительная информация для плана выполнения, когда появляется этот столбецUsing filesort , Using temporaryБудьте осторожны со словами, очень вероятно, что оператор SQL нуждается в оптимизации. |
Далее мы используем реальный пример оптимизации, чтобы проиллюстрировать процесс и методы оптимизации SQL-оптимизации.
Случай оптимизации
- Структура таблицы
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
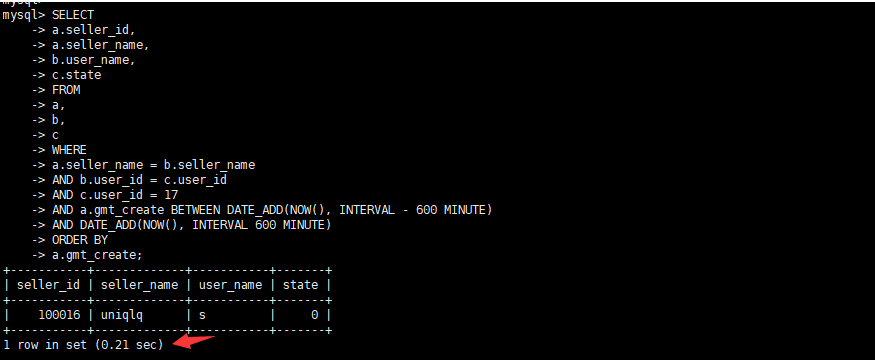
);- Три таблицы связаны для запроса состояния заказа текущего пользователя за 10 часов до и после текущего времени и упорядочивают их в порядке возрастания в соответствии со временем создания заказа.Конкретный SQL выглядит следующим образом.
select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;- Просмотр объема данных
- оригинальное время выполнения
- первоначальный план выполнения
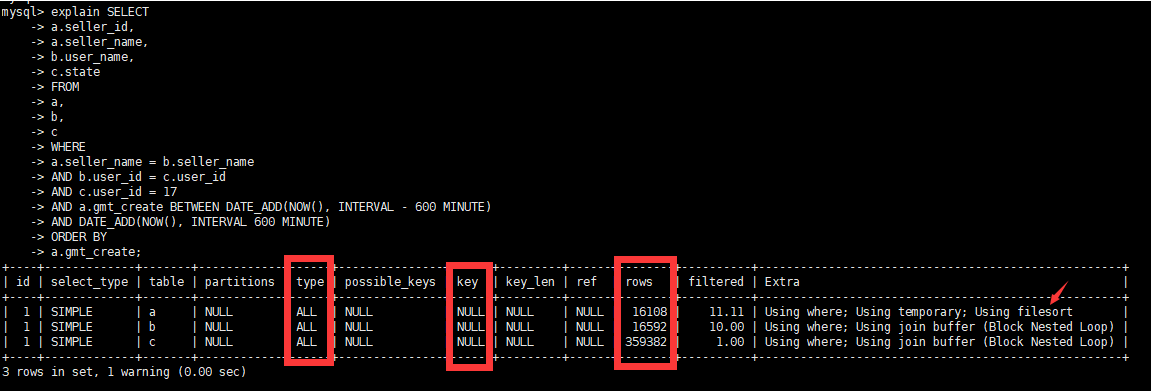
- Предварительные идеи оптимизации
- Тип поля условия where в SQL должен соответствовать структуре таблицы.
user_idЭто тип varchar(50), тип int, используемый фактическим SQL, имеет место неявное преобразование и индекс не добавляется. Таблица б и вuser_idПоле изменяется на тип int. - Поскольку существует связь между таблицей b и таблицей c, таблицы b и c
user_idсоздать индекс - Поскольку между таблицей и таблицей b существует связь, таблицы a и b
seller_nameСоздать индекс для поля - Устранение временных таблиц и сортировок с составными индексами
- Тип поля условия where в SQL должен соответствовать структуре таблицы.
- Предварительная оптимизация SQL
alter table b modify `user_id` int(10) DEFAULT NULL;
alter table c modify `user_id` int(10) DEFAULT NULL;
alter table c add index `idx_user_id`(`user_id`);
alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`);
alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);- Просмотр оптимизированного времени выполнения
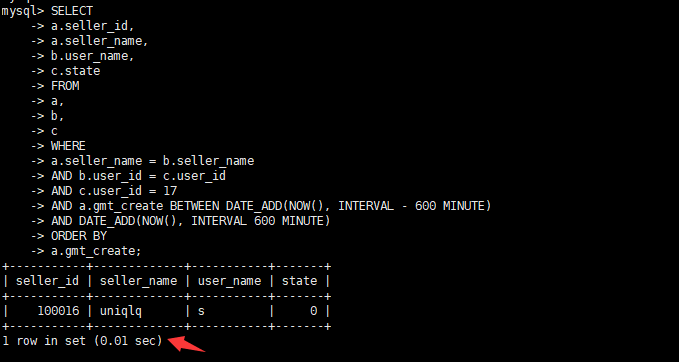- Просмотр оптимизированного плана выполнения
- Просмотр информации о предупреждениях
- продолжать оптимизировать
alter table a modify "gmt_create" datetime DEFAULT NULL; - Посмотреть время выполнения
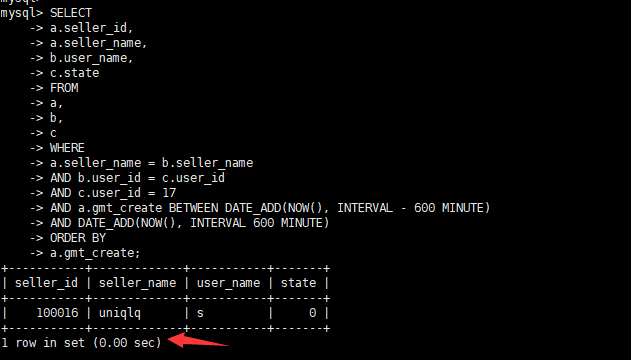- Посмотреть план выполнения
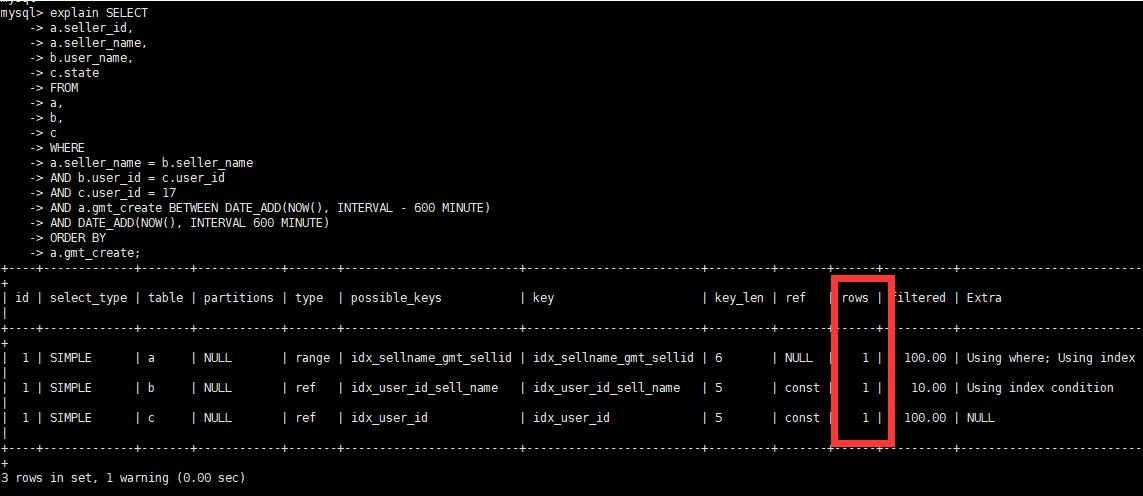
- Сводка по оптимизации
- Посмотреть план выполнения объяснить
- Если есть предупредительная информация, проверьте предупредительную информацию, чтобы показать предупреждения;
- Просмотр структуры таблицы и информации индекса, связанной с SQL
- Учитывать возможные точки оптимизации исходя из плана выполнения
- Выполнять такие операции, как изменение структуры таблицы, добавление индексов и перезапись SQL в соответствии с возможными точками оптимизации.
- Просмотр оптимизированного времени выполнения и планов выполнения
- Если эффект оптимизации не очевиден, повторите четвертый шаг.
Для получения дополнительной информации, пожалуйста, обратите внимание на публичный номер: JAVA Daily Record